 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Orchestrators: Constraint-Compliant Multi-Agent Optimization for Recommendation Systems
Jan 27, 2026Recommendation systems must optimize multiple objectives while satisfying hard business constraints such as fairness and coverage. For example, an e-commerce platform may require every recommendation list to include items from multiple sellers and at least one newly listed product; violating such constraints--even once--is unacceptable in production. Prior work on multi-objective recommendation and recent LLM-based recommender agents largely treat constraints as soft penalties or focus on item scoring and interaction, leading to frequent violations in real-world deployments. How to leverage LLMs for coordinating constrained optimization in recommendation systems remains underexplored. We propose DualAgent-Rec, an LLM-coordinated dual-agent framework for constrained multi-objective e-commerce recommendation. The framework separates optimization into an Exploitation Agent that prioritizes accuracy under hard constraints and an Exploration Agent that promotes diversity through unconstrained Pareto search. An LLM-based coordinator adaptively allocates resources between agents based on optimization progress and constraint satisfaction, while an adaptive epsilon-relaxation mechanism guarantees feasibility of final solutions. Experiments on the Amazon Reviews 2023 dataset demonstrate that DualAgent-Rec achieves 100% constraint satisfaction and improves Pareto hypervolume by 4-6% over strong baselines, while maintaining competitive accuracy-diversity trade-offs. These results indicate that LLMs can act as effective orchestration agents for deployable and constraint-compliant recommendation systems.
RobustExplain: Evaluating Robustness of LLM-Based Explanation Agents for Recommendation
Jan 27, 2026Large Language Models (LLMs) are increasingly used to generate natural-language explanations in recommender systems, acting as explanation agents that reason over user behavior histories. While prior work has focused on explanation fluency and relevance under fixed inputs, the robustness of LLM-generated explanations to realistic user behavior noise remains largely unexplored. In real-world web platforms, interaction histories are inherently noisy due to accidental clicks, temporal inconsistencies, missing values, and evolving preferences, raising concerns about explanation stability and user trust. We present RobustExplain, the first systematic evaluation framework for measuring the robustness of LLM-generated recommendation explanations. RobustExplain introduces five realistic user behavior perturbations evaluated across multiple severity levels and a multi-dimensional robustness metric capturing semantic, keyword, structural, and length consistency. Our goal is to establish a principled, task-level evaluation framework and initial robustness baselines, rather than to provide a comprehensive leaderboard across all available LLMs. Experiments on four representative LLMs (7B--70B) show that current models exhibit only moderate robustness, with larger models achieving up to 8% higher stability. Our results establish the first robustness benchmarks for explanation agents and highlight robustness as a critical dimension for trustworthy, agent-driven recommender systems at web scale.
Is More Context Always Better? Examining LLM Reasoning Capability for Time Interval Prediction
Jan 15, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning and prediction across different domains. Yet, their ability to infer temporal regularities from structured behavioral data remains underexplored. This paper presents a systematic study investigating whether LLMs can predict time intervals between recurring user actions, such as repeated purchases, and how different levels of contextual information shape their predictive behavior. Using a simple but representative repurchase scenario, we benchmark state-of-the-art LLMs in zero-shot settings against both statistical and machine-learning models. Two key findings emerge. First, while LLMs surpass lightweight statistical baselines, they consistently underperform dedicated machine-learning models, showing their limited ability to capture quantitative temporal structure. Second, although moderate context can improve LLM accuracy, adding further user-level detail degrades performance. These results challenge the assumption that "more context leads to better reasoning". Our study highlights fundamental limitations of today's LLMs in structured temporal inference and offers guidance for designing future context-aware hybrid models that integrate statistical precision with linguistic flexibility.
CEC-Zero: Zero-Supervision Character Error Correction with Self-Generated Rewards
Dec 30, 2025Large-scale Chinese spelling correction (CSC) remains critical for real-world text processing, yet existing LLMs and supervised methods lack robustness to novel errors and rely on costly annotations. We introduce CEC-Zero, a zero-supervision reinforcement learning framework that addresses this by enabling LLMs to correct their own mistakes. CEC-Zero synthesizes errorful inputs from clean text, computes cluster-consensus rewards via semantic similarity and candidate agreement, and optimizes the policy with PPO. It outperforms supervised baselines by 10--13 F$_1$ points and strong LLM fine-tunes by 5--8 points across 9 benchmarks, with theoretical guarantees of unbiased rewards and convergence. CEC-Zero establishes a label-free paradigm for robust, scalable CSC, unlocking LLM potential in noisy text pipelines.
Adaptive Multi-view Graph Contrastive Learning via Fractional-order Neural Diffusion Networks
Nov 09, 2025Graph contrastive learning (GCL) learns node and graph representations by contrasting multiple views of the same graph. Existing methods typically rely on fixed, handcrafted views-usually a local and a global perspective, which limits their ability to capture multi-scale structural patterns. We present an augmentation-free, multi-view GCL framework grounded in fractional-order continuous dynamics. By varying the fractional derivative order $α\in (0,1]$, our encoders produce a continuous spectrum of views: small $α$ yields localized features, while large $α$ induces broader, global aggregation. We treat $α$ as a learnable parameter so the model can adapt diffusion scales to the data and automatically discover informative views. This principled approach generates diverse, complementary representations without manual augmentations. Extensive experiments on standard benchmarks demonstrate that our method produces more robust and expressive embeddings and outperforms state-of-the-art GCL baselines.
MetaSynth: Multi-Agent Metadata Generation from Implicit Feedback in Black-Box Systems
Oct 01, 2025Meta titles and descriptions strongly shape engagement in search and recommendation platforms, yet optimizing them remains challenging. Search engine ranking models are black box environments, explicit labels are unavailable, and feedback such as click-through rate (CTR) arrives only post-deployment. Existing template, LLM, and retrieval-augmented approaches either lack diversity, hallucinate attributes, or ignore whether candidate phrasing has historically succeeded in ranking. This leaves a gap in directly leveraging implicit signals from observable outcomes. We introduce MetaSynth, a multi-agent retrieval-augmented generation framework that learns from implicit search feedback. MetaSynth builds an exemplar library from top-ranked results, generates candidate snippets conditioned on both product content and exemplars, and iteratively refines outputs via evaluator-generator loops that enforce relevance, promotional strength, and compliance. On both proprietary e-commerce data and the Amazon Reviews corpus, MetaSynth outperforms strong baselines across NDCG, MRR, and rank metrics. Large-scale A/B tests further demonstrate 10.26% CTR and 7.51% clicks. Beyond metadata, this work contributes a general paradigm for optimizing content in black-box systems using implicit signals.
Spatial Reasoning in Foundation Models: Benchmarking Object-Centric Spatial Understanding
Sep 26, 2025
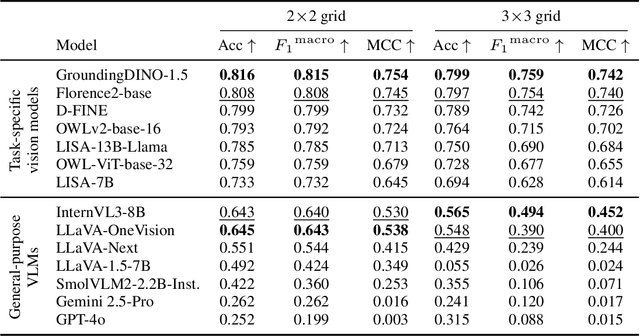

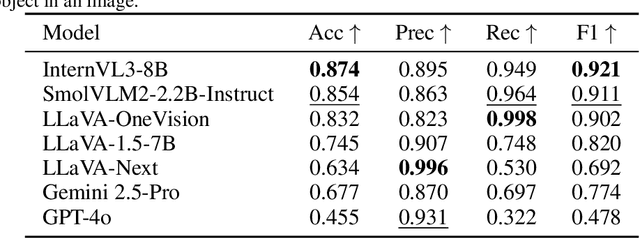
Spatial understanding is a critical capability for vision foundation models. While recent advances in large vision models or vision-language models (VLMs) have expanded recognition capabilities, most benchmarks emphasize localization accuracy rather than whether models capture how objects are arranged and related within a scene. This gap is consequential; effective scene understanding requires not only identifying objects, but reasoning about their relative positions, groupings, and depth. In this paper, we present a systematic benchmark for object-centric spatial reasoning in foundation models. Using a controlled synthetic dataset, we evaluate state-of-the-art vision models (e.g., GroundingDINO, Florence-2, OWLv2) and large VLMs (e.g., InternVL, LLaVA, GPT-4o) across three tasks: spatial localization, spatial reasoning, and downstream retrieval tasks. We find a stable trade-off: detectors such as GroundingDINO and OWLv2 deliver precise boxes with limited relational reasoning, while VLMs like SmolVLM and GPT-4o provide coarse layout cues and fluent captions but struggle with fine-grained spatial context. Our study highlights the gap between localization and true spatial understanding, and pointing toward the need for spatially-aware foundation models in the community.
Millisecond-Response Tracking and Gazing System for UAVs: A Domestic Solution Based on "Phytium + Cambricon"
Sep 04, 2025In the frontier research and application of current video surveillance technology, traditional camera systems exhibit significant limitations of response delay exceeding 200 ms in dynamic scenarios due to the insufficient deep feature extraction capability of automatic recognition algorithms and the efficiency bottleneck of computing architectures, failing to meet the real-time requirements in complex scenes. To address this issue, this study proposes a heterogeneous computing architecture based on Phytium processors and Cambricon accelerator cards, constructing a UAV tracking and gazing system with millisecond-level response capability. At the hardware level, the system adopts a collaborative computing architecture of Phytium FT-2000/4 processors and MLU220 accelerator cards, enhancing computing power through multi-card parallelism. At the software level, it innovatively integrates a lightweight YOLOv5s detection network with a DeepSORT cascaded tracking algorithm, forming a closed-loop control chain of "detection-tracking-feedback". Experimental results demonstrate that the system achieves a stable single-frame comprehensive processing delay of 50-100 ms in 1920*1080 resolution video stream processing, with a multi-scale target recognition accuracy of over 98.5%, featuring both low latency and high precision. This study provides an innovative solution for UAV monitoring and the application of domestic chips.
PoRe: Position-Reweighted Visual Token Pruning for Vision Language Models
Aug 25, 2025Vision-Language Models (VLMs) typically process a significantly larger number of visual tokens compared to text tokens due to the inherent redundancy in visual signals. Visual token pruning is a promising direction to reduce the computational cost of VLMs by eliminating redundant visual tokens. The text-visual attention score is a widely adopted criterion for visual token pruning as it reflects the relevance of visual tokens to the text input. However, many sequence models exhibit a recency bias, where tokens appearing later in the sequence exert a disproportionately large influence on the model's output. In VLMs, this bias manifests as inflated attention scores for tokens corresponding to the lower regions of the image, leading to suboptimal pruning that disproportionately retains tokens from the image bottom. In this paper, we present an extremely simple yet effective approach to alleviate the recency bias in visual token pruning. We propose a straightforward reweighting mechanism that adjusts the attention scores of visual tokens according to their spatial positions in the image. Our method, termed Position-reweighted Visual Token Pruning, is a plug-and-play solution that can be seamlessly incorporated into existing visual token pruning frameworks without any changes to the model architecture or extra training. Extensive experiments on LVLMs demonstrate that our method improves the performance of visual token pruning with minimal computational overhead.
CC-Time: Cross-Model and Cross-Modality Time Series Forecasting
Aug 17, 2025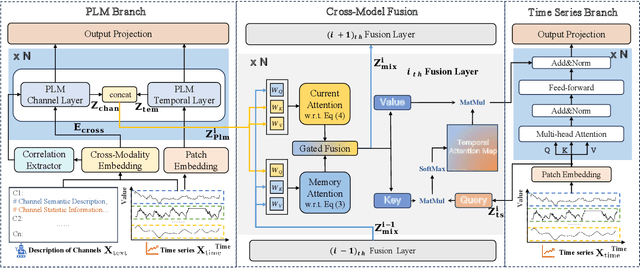
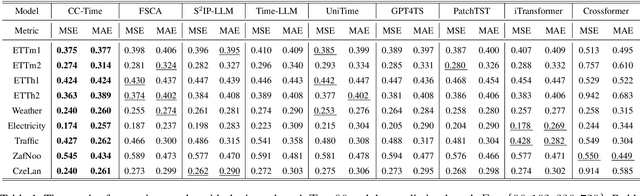

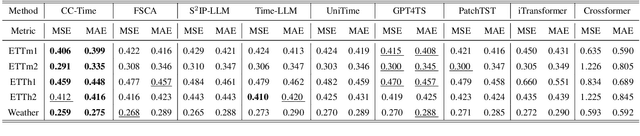
With the success of pre-trained language models (PLMs) in various application fields beyond natural language processing, language models have raised emerging attention in the field of time series forecasting (TSF) and have shown great prospects. However, current PLM-based TSF methods still fail to achieve satisfactory prediction accuracy matching the strong sequential modeling power of language models. To address this issue, we propose Cross-Model and Cross-Modality Learning with PLMs for time series forecasting (CC-Time). We explore the potential of PLMs for time series forecasting from two aspects: 1) what time series features could be modeled by PLMs, and 2) whether relying solely on PLMs is sufficient for building time series models. In the first aspect, CC-Time incorporates cross-modality learning to model temporal dependency and channel correlations in the language model from both time series sequences and their corresponding text descriptions. In the second aspect, CC-Time further proposes the cross-model fusion block to adaptively integrate knowledge from the PLMs and time series model to form a more comprehensive modeling of time series patterns. Extensive experiments on nine real-world datasets demonstrate that CC-Time achieves state-of-the-art prediction accuracy in both full-data training and few-shot learning situations.